Inferencing Options - TGI, VLLM, Ollama, and Triton
- Chandan Kumar
- Nov 15, 2024
- 4 min read
As AI applications become more selecting the right tool for model inference, scalability, and performance is increasingly important. Let’s break down the unique offerings, key features, and examples for each tool.
Text Generation Inference (TGI)
Overview: Developed by Hugging Face, TGI (Text Generation Inference) is a specialized inference tool for serving large language models (LLMs) efficiently. TGI is tailored for production environments where high throughput and low latency are essential, making it a popular choice for real-time applications.
Key Features:
Efficient Model Hosting: Optimized for large language models like GPT, BERT, and custom Hugging Face models.
Asynchronous and Batch Processing: Supports both asynchronous calls and batch processing, allowing it to handle high volumes of requests.
Quantization Support: Reduces model memory footprint via quantization techniques (such as FP16 and INT8), making it suitable for resource-constrained deployments.
Scalability: Integrates with scaling solutions like Kubernetes and autoscaling, facilitating large-scale deployments.
Hugging Face Ecosystem: Seamlessly integrates with Hugging Face’s model library and datasets.
Real-World Application:
A popular use case is serving chatbots for customer support, where TGI provides fast responses and can handle fluctuations in demand by scaling automatically.
Integrating in your code ( T5 example )
import torch
from transformers import T5Tokenizer, T5ForConditionalGeneration
# Load pre-trained TGI model and tokenizer
tokenizer = T5Tokenizer.from_pretrained('tgi-base')
model = T5ForConditionalGeneration.from_pretrained('tgi-base')
# Define prompt
prompt = "Write a short story about a character who learns to play the guitar."
# Generate text
input_ids = tokenizer.encode(prompt, return_tensors='pt')
output = model.generate(input_ids, max_length=200)
# Print generated text
print(tokenizer.decode(output[0], skip_special_tokens=True))Directly Serving in a model
# Install TGI via pip
pip install tgi
# Run TGI with a Hugging Face model
tgi serve --model gpt-neo-2.7BVLLM
Overview: VLLM is an open-source inference engine specifically designed for efficient large language model inference, especially when running on GPUs. Developed by UC Berkeley, it introduces an innovative memory management technique called Token Parallelism, which optimizes GPU memory usage, enabling it to handle models larger than typical GPU memory.
Key Features:
Token Parallelism: Reduces memory requirements by breaking down inference into smaller, manageable tokens.
Efficient Resource Allocation: Minimizes GPU memory wastage, making it ideal for large-scale deployments.
Multi-GPU Support: Can distribute models across multiple GPUs to maximize throughput and reduce latency.
Dynamic Batching: Automatically adjusts batch sizes based on workload, ensuring optimal performance.
Real-World Application:
VLLM is often used for serving large LLMs in cost-sensitive environments, such as educational or enterprise applications, where efficient memory utilization is paramount.
Code Example:
import torch
from PIL import Image
from transformers import ViLTForImageClassification, ViLTFeatureExtractor
# Load pre-trained VLLM model and feature extractor
model = ViLTForImageClassification.from_pretrained('vllm-base')
feature_extractor = ViLTFeatureExtractor.from_pretrained('vllm-base')
# Load image
image = Image.open('image.jpg')
# Preprocess image
inputs = feature_extractor(images=image, return_tensors='pt')
# Generate caption
outputs = model(**inputs)
caption = torch.argmax(outputs.logits)
# Print generated caption
print(caption) Directly Serving a model
# Install VLLM
pip install vllm
# Run a model with VLLM
vllm --model gpt-3 --num_gpus 2Ollama
Overview: Ollama is a platform optimized for working with foundation models, especially LLaMA-based models. It provides tools and APIs to make it easy for developers to use models in applications without extensive setup. Ollama’s tools allow for rapid prototyping and are accessible even for developers new to large language models.
Key Features:
Optimized for LLaMA Models: Designed to work specifically with LLaMA models, with minimal setup required.
Cross-Platform Availability: Runs seamlessly on macOS and Windows, catering to a broad developer base.
Local and Cloud Deployment: Offers flexibility to deploy models locally or in the cloud, enabling efficient testing and scaling.
Interactive CLI and API Support: Provides a user-friendly command-line interface and API for model interaction.
Real-World Application:
Developers can use Ollama to create language analysis tools, personal AI assistants, or research-focused applications with LLaMA models. Its ease of use and platform flexibility make it popular for smaller teams and solo developers.
Code Example:
import ollama
# Load the model
ollama_model = ollama.Model("llama-2")
response = ollama_model.generate("Explain quantum physics in simple terms.")
print(response) Start Serving the model
# Assuming Ollama is installed on macOS (requires macOS 13+)
ollama serve --model llama-2
# Or for direct queries:
ollama run llama-2 "Tell me a joke" NVIDIA Triton Inference Server
Overview: Triton is an inference server by NVIDIA that allows enterprises to deploy, scale, and manage ML models in production environments. It supports multiple frameworks and model formats, making it highly versatile and suitable for diverse use cases.
Key Features:
Framework Agnostic: Supports PyTorch, TensorFlow, ONNX, and more, allowing for heterogeneous model deployments.
Multi-Model Inference: Can deploy multiple models simultaneously on a single server, handling diverse workloads.
Dynamic Batching and Multi-GPU Scaling: Enables efficient GPU utilization through batching and model parallelism across multiple GPUs.
Integration with NVIDIA Hardware: Optimized for NVIDIA’s GPU stack, allowing maximum performance for GPU-based deployments.
Model Ensemble Support: Allows models to be chained or used together for more complex workflows (e.g., text to vision pipeline).
Real-World Application:
Triton is widely used in enterprise settings where multiple AI models need to be deployed, such as in recommendation engines, image classification pipelines, and NLP applications requiring high throughput.
Code Example:
import tritonclient
# Create Triton client
client = tritonclient.InferenceServerClient('localhost:8000')
# Load model
model_name = 'tgi-base'
# Define input
input_data = {'prompt': 'Write a short story about a character who learns to play the guitar.'}
# Make inference request
response = client.infer(model_name, input_data)
# Print response
print(response.get_response()) Comparative Table
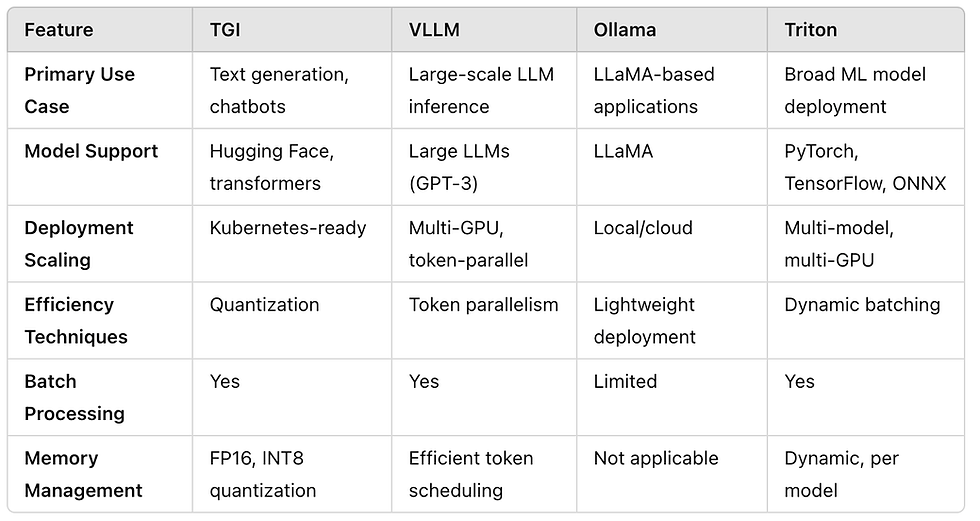
Comparison table Ollama TGI, vllm and Triton
Conclusion
Each of these tools serves distinct roles within AI and ML pipelines. For high-performance text generation, TGI is an excellent choice with its Hugging Face integration and quantization support. VLLM excels with memory efficiency and is ideal for LLM inference on GPUs. Ollama simplifies working with LLaMA models for developers interested in quick prototyping and deployment. Lastly, Triton is the most versatile, supporting a wide range of models and frameworks, making it a go-to for production-grade, multi-model deployments.
Comments